因果卷积
casual卷积最初随WaveNet一起提出,WaveNet是一个生成模型,类似于早期的pixel RNN和Pixel CNN,主要用来生成语音,声音元素是一个点一个点生成的。WaveNet是利用卷积来学习t时刻之前的输入数据(音频),来预测t+1时刻的输出. 对输入数据的顺序很注重, t时刻的输出仅仅依赖于1,2,…,t-1时刻的输入,不会依赖于t+1时刻以及之后时刻的输入。这与BiLSTM的思想截然不同。

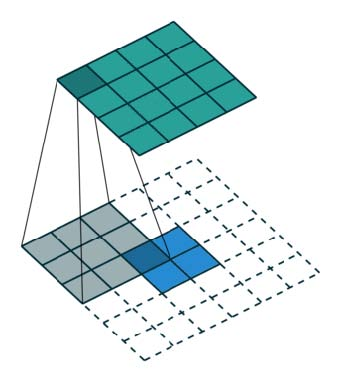
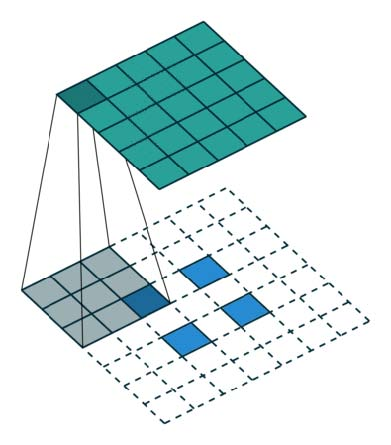
由于声音文件是时间上的一维数组,16KHz的采样率的文件,每秒钟就会有16000个元素,而上面所说的因果卷积的感受野非常小,即使堆叠很多层也只能使用到很少的数据来生成t时刻的的元素,为了扩大卷积的感受野,WaveNet采用了堆叠了(stack)多层扩张(dilated )卷积(中篇里有提到)来增大网络的感受野,使得网络生成下一个元素的时候,能够使用更多之前的元素数值。1D扩张卷积如下图所示:
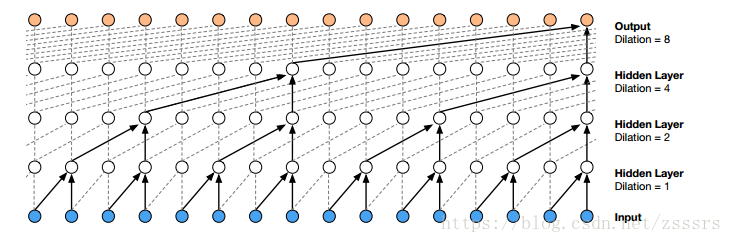
整个生成过程的动态图如下: